
My First Few Hours With Claude Opus 4.6: It Feels Different
Anthropic released Opus 4.6 a few hours ago. I dropped everything to try it. The one-shotting is real, the vibe is different, and the writing might actually be worse.
I’ve been using Claude models since the Opus 3 days. Opus 4.5 was my daily driver for months. So when Anthropic dropped Opus 4.6 a few hours ago, I immediately switched over and started throwing tasks at it.
Its been maybe three hours. Very early impressions. But a few things jumped out.
The Benchmarks
First, the numbers. Opus 4.6 leads on most major evaluations against GPT-5.2, Gemini 3 Pro, and its predecessor Opus 4.5:
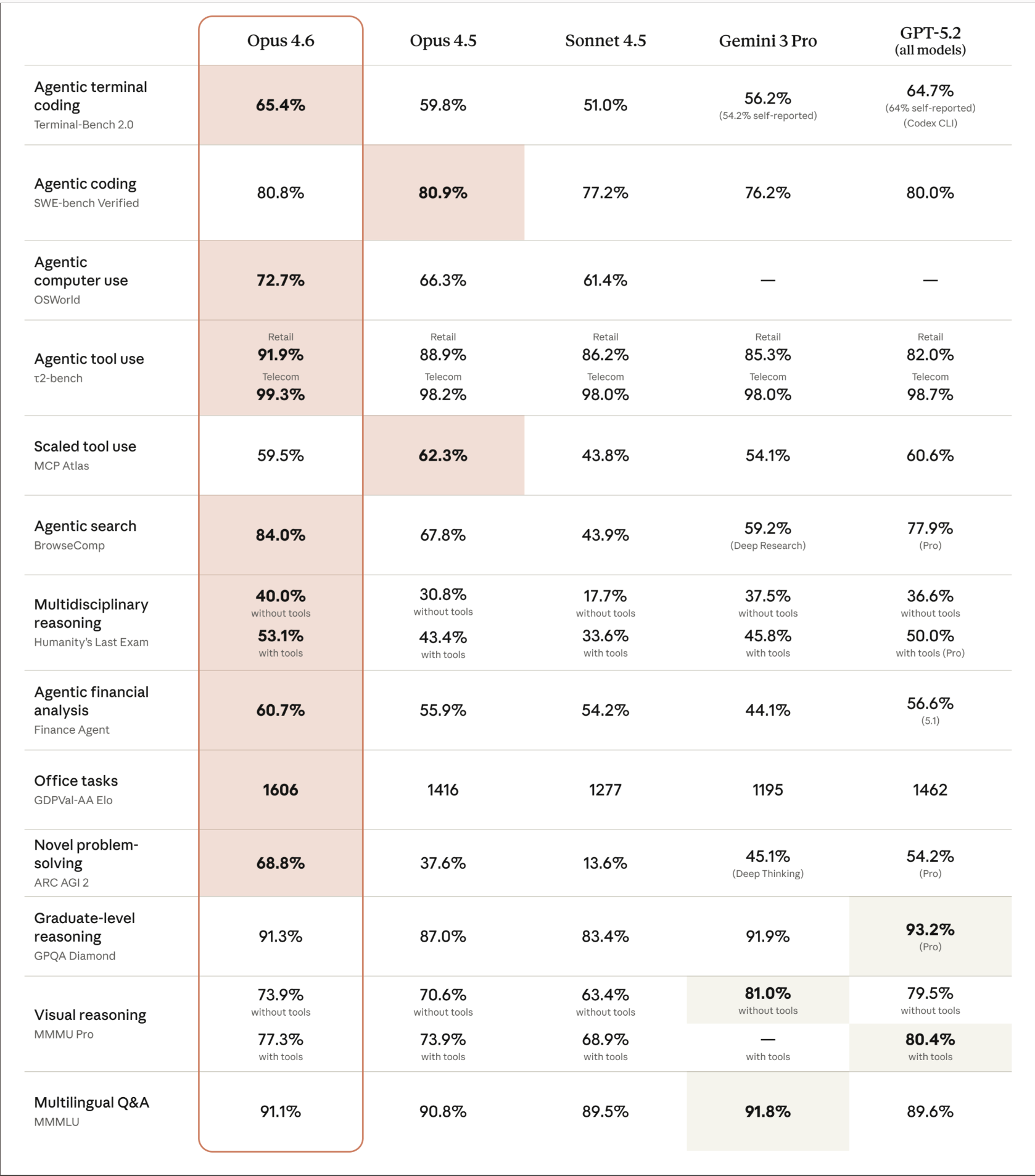
The highlights: 65.4% on Terminal-Bench 2.0 (agentic coding), 84.0% on BrowseComp (agentic search), 72.7% on OSWorld, and a massive 1606 Elo on GDPVal-AA which measures real knowledge work tasks. That last one is 144 points above GPT-5.2.
The One-Shotting Is Real
This is the first thing I noticed. Opus 4.6 one-shots things that used to take two or three rounds of back and forth.
I asked it to scaffold an API endpoint with input validation, error handling, and rate limiting. With 4.5, I’d typically need to nudge it on an edge case or two. With 4.6, the first output was done. Not “pretty close,” done. It even added request logging in the format we use elsewhere, which I hadnt mentioned.
Same thing with a react component with proper accessibility attributes, a postgres migration with working rollback, a utility function where it nailed the typescript generics first try. Things that previously needed a correction pass just worked.
It Feels Different
Hard to articulate, but 4.6 feels like talking to a more senior engineer. Opus 4.5 had a certain eagerness to it. It would over-explain, add comments on every line, suggest three approaches when you clearly just wanted one.
4.6 is calmer. More opinionated. When I ask it to pick an approach, it picks one and commits. The adaptive thinking probably helps here, it seems to guage the complexity of what you’re asking and calibrate accordingly. Quick questions get quick answers. Complex stuff gets deep reasoning. I didn’t configure anything.
The Writing Got Worse Though
Ok heres the thing nobody is going to want to hear. The writing is worse.
Not for casual stuff, thats fine. But for technical documentation, product specs, that kind of thing? Its noticeably more robotic than 4.5. The structure is more rigid. The explanations feel more like theyre being generated by something that optimized really hard for being correct and lost some of the natural flow in the process.
My theory is that all the RL training they did to improve the reasoning and coding capabilities came at a cost. When you optimize a model heavily for complex reasoning, chain of thought, benchmark performance, it starts to feel like its “thinking out loud” even when you just need it to write clearly. The writing has this subtle over-structured quality to it now, like every paragraph is trying to be a logical argument instead of just communicating an idea.
Opus 4.5 had a warmth to its writing that 4.6 seems to have lost a bit. Its still better than GPT-5.2 for writing imo, but the gap between 4.5 and 4.6 is noticable and its not in 4.6’s favor.
This is a real tradeoff and I hope Anthropic is aware of it.
Early Verdict
Three hours isnt enough for a real review. But the coding improvements are legit, the one-shotting alone changes the workflow. The writing regression is dissapointing though, especially for those of us who use Claude for both code and prose.
The pricing is identical to 4.5, so if you primarily use Claude for coding, switch now. If you use it heavily for writing and documentation, maybe keep 4.5 around too.
I’ll do a proper review after a full week. But so far its a mixed bag, just one thats weighted heavily toward the positive side.